Ollama介绍
ollama是一个开源大模型综合管理和使用平台,不仅单模态模型,还支持多模态模型,以及正在开发支持扩散模型!
ollama目前在macOS、Linux、Windows上都可以运行使用!
官方地址:https://ollama.com/
在Windows安装Ollama
直接从下载页面下载相对应的安装程序,Windows安装程序选择Windows的安装包,点击“Download for Windows(Preview)”
下载下来之后是一个exe的安装文件,双击安装即可!
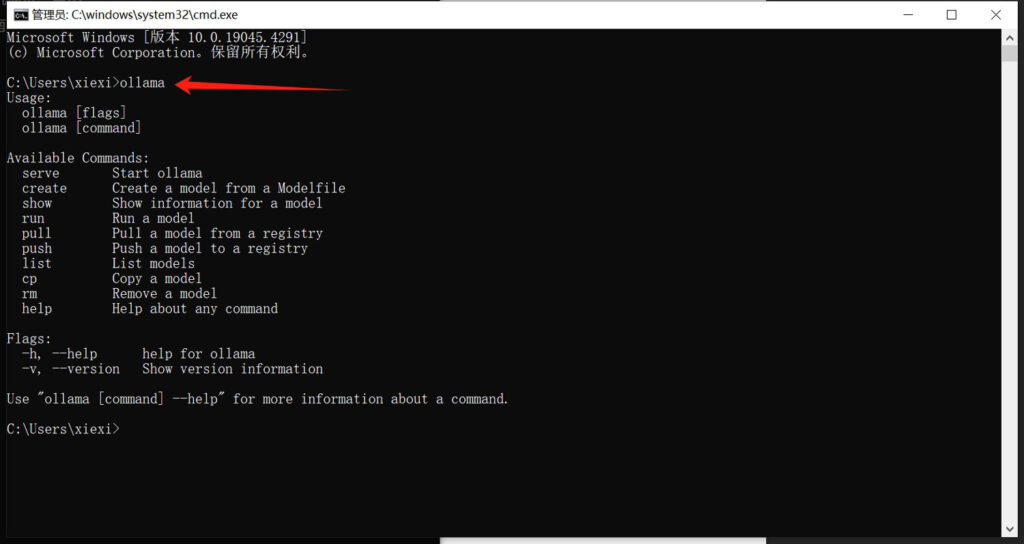
安装完成之后,打开一个cmd命令窗口,输入“ollama”命令,如果显示ollama相关的信息就证明安装已经成功了!
单独使用ollama下载模型
为什么说是单独使用ollama呢,这是因为我们后面会讲和open webui结合使用的方法!
事实上我们安装ollama完成之后,只需要下载大模型,便可以直接通过cmd命令提示窗口来与大模型进行交互了!只不过这种方式体验感不好,我们后面会介绍我们熟悉的类ChatGPT的网页交互的方式。
如果你想了解从cmd命令窗口和大模型交互的方式,你可以继续往下看
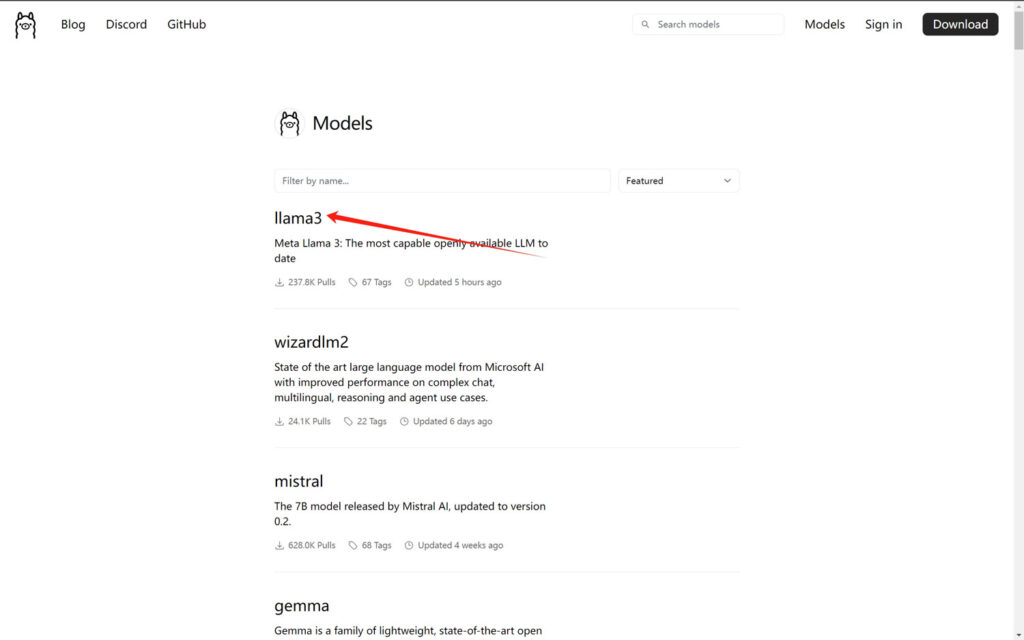
Ollama的模型库提供了多种大型语言模型供用户选择。你可以通过访问Ollama模型库来找到并下载你需要的模型。
模型库的地址:https://ollama.com/library
1.从模型库选择一个模型
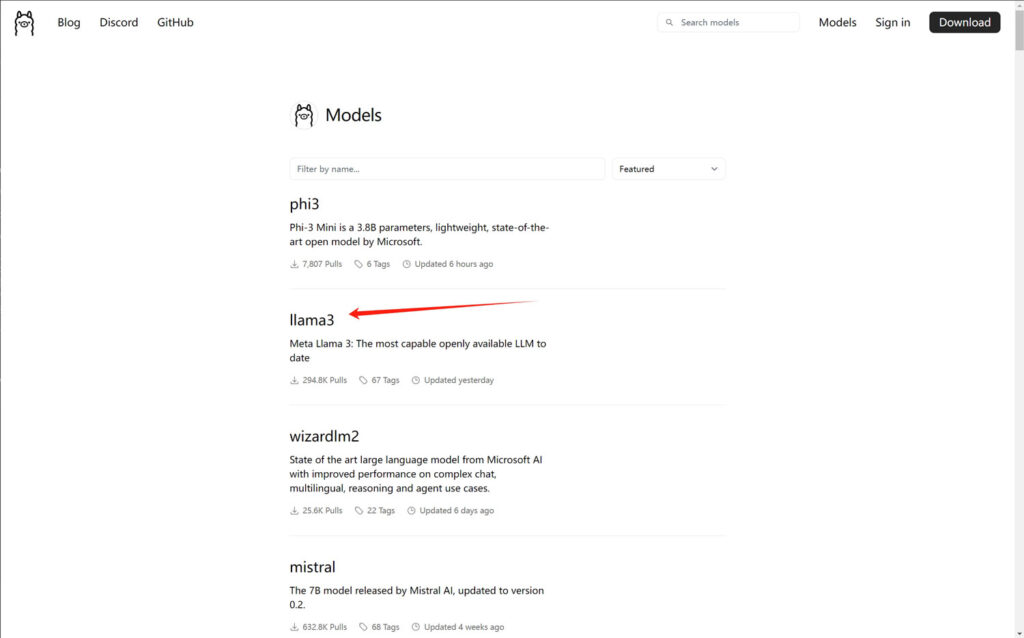
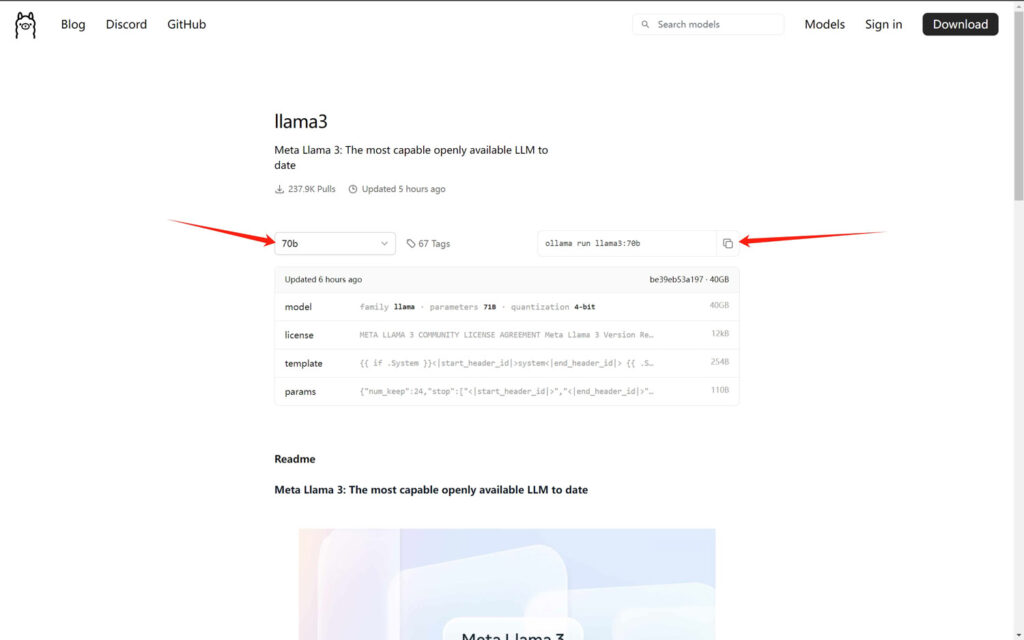
2.选择一个版本,然后点击后面的复制命令按钮
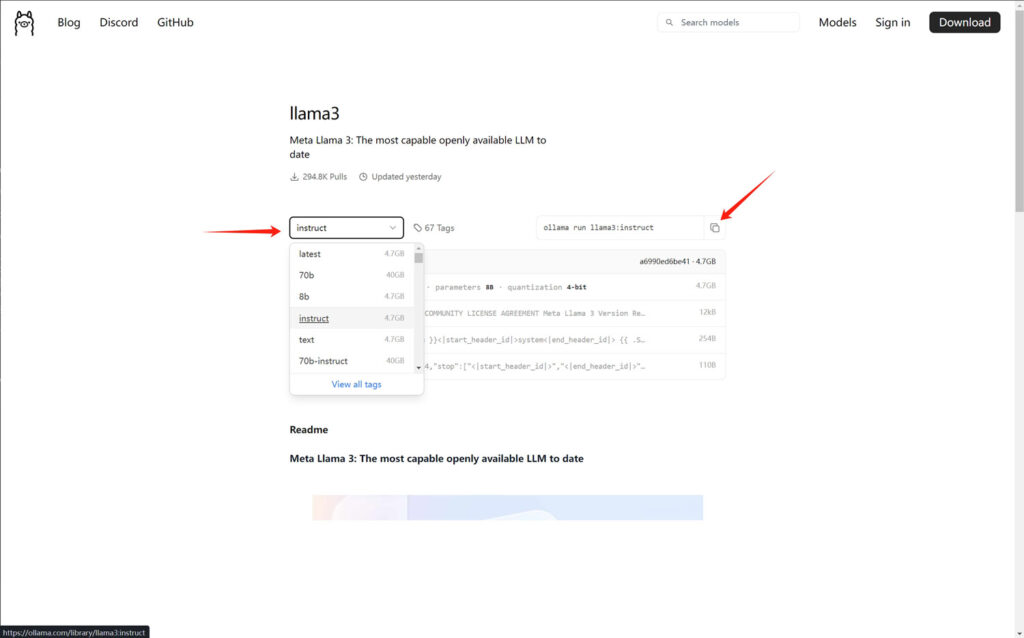
3.直接将复制的命令粘贴到cmd命令窗口,回车执行即可进入到模型的下载过程!
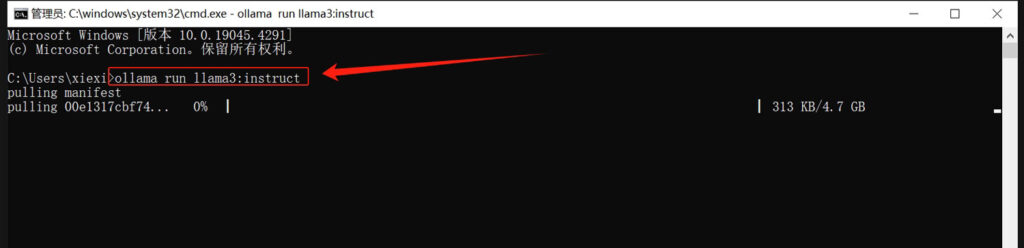
单独使用ollama与大模型交互
ollama的大模型默认保存的路径是:
macOS: ~/.ollama/models.
Linux: /usr/share/ollama/.ollama/models.
Windows: C:Users<username>.ollamamodels
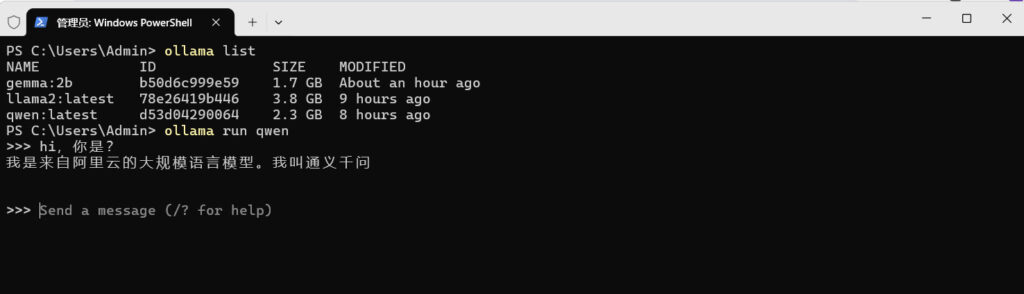
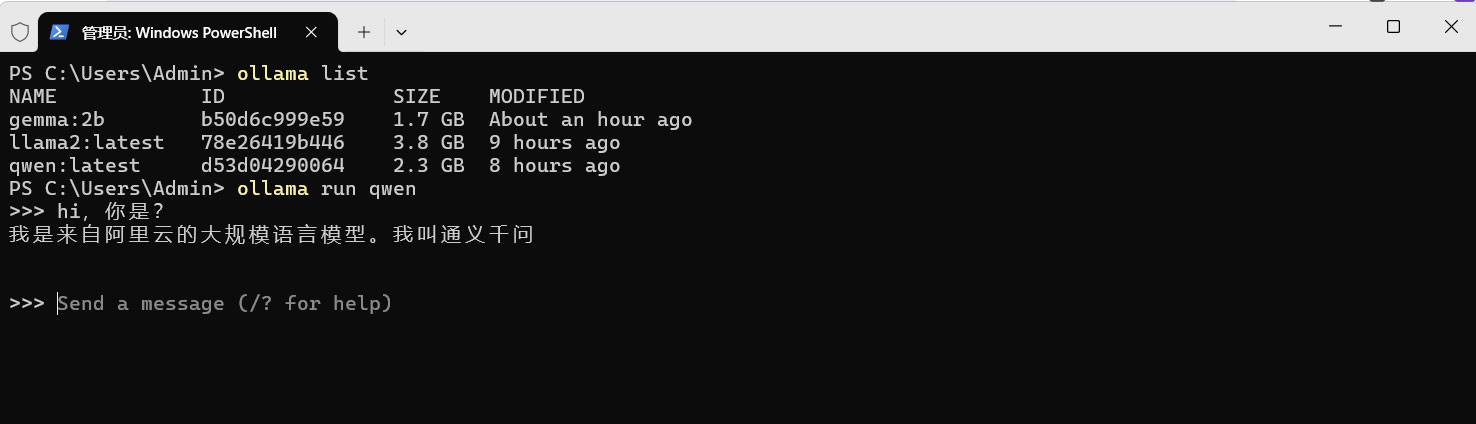
可以通过如下的命令来查看模型列表
ollama listPS C:UsersAdmin> ollama list
NAME ID SIZE MODIFIED
gemma:2b b50d6c999e59 1.7 GB About an hour ago
llama2:latest 78e26419b446 3.8 GB 9 hours ago
qwen:latest d53d04290064 2.3 GB 8 hours ago
PS C:UsersAdmin>通过ollama run命令,你可以运行特定的模型。例如,ollama run qwen将启动qwen模型。
Open WebUI
Open WebUI介绍
open webui程序官网:https://openwebui.com/
open webui GitHub主页:https://github.com/open-webui/open-webui
Open WebUI 是一个可扩展、功能丰富且用户友好的自托管 WebUI,旨在完全离线操作。它支持各种 LLM 运行程序,包括 Ollama 和 OpenAI 兼容的 API。还可以通过AUTOMATIC1111和ComfyUI的API来整合稳定扩散模型,实现LLM指导SD来生成图片!
特点⭐
🖥️直观的界面:我们的聊天界面从 ChatGPT 中汲取灵感,确保用户友好的体验。
📱响应式设计:在桌面和移动设备上享受无缝体验。
⚡快速响应:享受快速响应的性能。
🚀轻松设置:使用 Docker 或 Kubernetes(kubectl、kustomize 或 helm)无缝安装,以获得无忧体验。
🌈主题定制:从各种主题中进行选择,个性化您的 Open WebUI 体验。
💻代码语法突出显示:通过我们的语法突出显示功能增强代码的可读性。
✒️🔢完整的 Markdown 和 LaTeX 支持:通过全面的 Markdown 和 LaTeX 功能来丰富交互,提升您的 LLM 体验。
📚本地 RAG 集成:通过突破性的检索增强生成 (RAG) 支持深入了解聊天交互的未来。此功能将文档交互无缝集成到您的聊天体验中。您可以将文档直接加载到聊天中或将文件添加到文档库中,使用#提示中的命令轻松访问它们。在 alpha 阶段,当我们积极完善和增强此功能以确保最佳性能和可靠性时,可能会偶尔出现问题。
🔍 RAG 嵌入支持:直接在文档设置中更改 RAG 嵌入模型,增强文档处理。此功能支持 Ollama 和 OpenAI 模型。
🌐网页浏览功能#:使用URL 后的命令将网站无缝集成到您的聊天体验中。此功能允许您将网络内容直接合并到您的对话中,从而增强交互的丰富性和深度。
📜提示预设支持/:使用聊天输入中的命令立即访问预设提示。轻松加载预定义的对话开头并加快您的互动。通过Open WebUI Community集成轻松导入提示。
👍👎 RLHF 注释:通过对消息进行“赞成”和“反对”评级来增强您的消息,然后选择提供文本反馈,从而促进根据人类反馈 (RLHF) 创建强化学习数据集。利用您的消息来训练或微调模型,同时确保本地保存数据的机密性。
🏷️对话标记:轻松分类和定位特定聊天,以便快速参考和简化数据收集。
📥🗑️下载/删除模型:直接从 Web UI 轻松下载或删除模型。
🔄更新所有 Ollama 模型:使用方便的按钮一次轻松更新本地安装的模型,简化模型管理。
⬆️ GGUF 文件模型创建:通过直接从 Web UI 上传 GGUF 文件,轻松创建 Ollama 模型。简化的流程,可选择从您的计算机上传或从 Hugging Face 下载 GGUF 文件。
🤖多模型支持:不同聊天模型之间无缝切换,实现多样化交互。
🔄多模式支持:与支持多模式交互的模型无缝交互,包括图像(例如 LLava)。
🧩模型文件生成器:通过 Web UI 轻松创建 Ollama 模型文件。通过开放 WebUI 社区集成轻松创建和添加角色/代理、自定义聊天元素以及导入模型文件。
⚙️多个模特对话:轻松地同时与多个模特互动,利用他们的独特优势来获得最佳响应。通过并行利用一组不同的模型来增强您的体验。
💬协作聊天:通过无缝编排群组对话来利用多个模型的集体智慧。使用@命令指定模型,在聊天界面中启用动态且多样化的对话。让自己沉浸在聊天环境中的集体智慧中。
🗨️本地聊天共享:在用户之间无缝生成和共享聊天链接,增强协作和沟通。
🔄再生历史访问:轻松重新访问和探索您的整个再生历史。
📜聊天历史记录:轻松访问和管理您的对话历史记录。
📬存档聊天:轻松存储与法学硕士的完整对话以供将来参考,保持聊天界面整洁有序,同时方便检索和参考。
📤📥导入/导出聊天历史记录:将您的聊天数据无缝移入和移出平台。
🗣️语音输入支持:通过语音交互与您的模型互动;享受直接与模特交谈的便利。此外,探索在 3 秒静音后自动发送语音输入的选项,以获得简化的体验。
🔊可配置的文本转语音端点:使用可配置的 OpenAI 端点自定义您的文本转语音体验。
⚙️使用高级参数进行微调控制:通过调整温度等参数和定义系统提示来获得更深层次的控制,以根据您的特定偏好和需求定制对话。
🎨🤖图像生成集成:使用 AUTOMATIC1111 API(本地)、ComfyUI(本地)和 DALL-E 等选项无缝集成图像生成功能,通过动态视觉内容丰富您的聊天体验。
🤝 OpenAI API 集成:轻松集成 OpenAI 兼容 API,与 Ollama 模型进行多功能对话。自定义 API 基本 URL 以链接到LMStudio、Mistral、OpenRouter 等。
✨多种 OpenAI 兼容 API 支持:无缝集成和定制各种 OpenAI 兼容 API,增强聊天交互的多功能性。
🔑 API 密钥生成支持:生成密钥以利用 Open WebUI 和 OpenAI 库,简化集成和开发。
🔗外部 Ollama 服务器连接:通过配置环境变量无缝链接到托管在不同地址上的外部 Ollama 服务器。
🔀多个 Ollama 实例负载平衡:轻松地在多个 Ollama 实例之间分配聊天请求,以增强性能和可靠性。
👥多用户管理:通过我们直观的管理面板轻松监督和管理用户,简化用户管理流程。
🔗 Webhook 集成:通过 webhook 订阅新用户注册事件(兼容 Google Chat 和 Microsoft Teams),提供实时通知和自动化功能。
🛡️模型白名单:管理员可以将具有“用户”角色的用户的模型列入白名单,从而增强安全性和访问控制。
📧可信电子邮件身份验证:使用可信电子邮件标头进行身份验证,添加额外的安全和身份验证层。
🔐基于角色的访问控制(RBAC):通过受限的权限确保安全访问;只有经过授权的个人才能访问您的 Ollama,并且为管理员保留专有的模型创建/拉取权限。
🔒后端反向代理支持:通过 Open WebUI 后端和 Ollama 之间的直接通信增强安全性。这一关键功能消除了通过 LAN 公开 Ollama 的需要。从 Web UI 向“/ollama/api”路由发出的请求会从后端无缝重定向到 Ollama,从而增强整体系统安全性。
🌐🌍多语言支持:借助我们的国际化 (i18n) 支持,以您喜欢的语言体验开放式 WebUI。加入我们,扩展我们支持的语言!我们正在积极寻找贡献者!
🌟持续更新:我们致力于通过定期更新和新功能来改进 Open WebUI。
在Windows安装Open WebUI
本教程以Windows10为例,如果你是Windows11,下面关于wsl的步骤略有不同,Windows11不需要单独安装wsl,请注意!
安装wsl
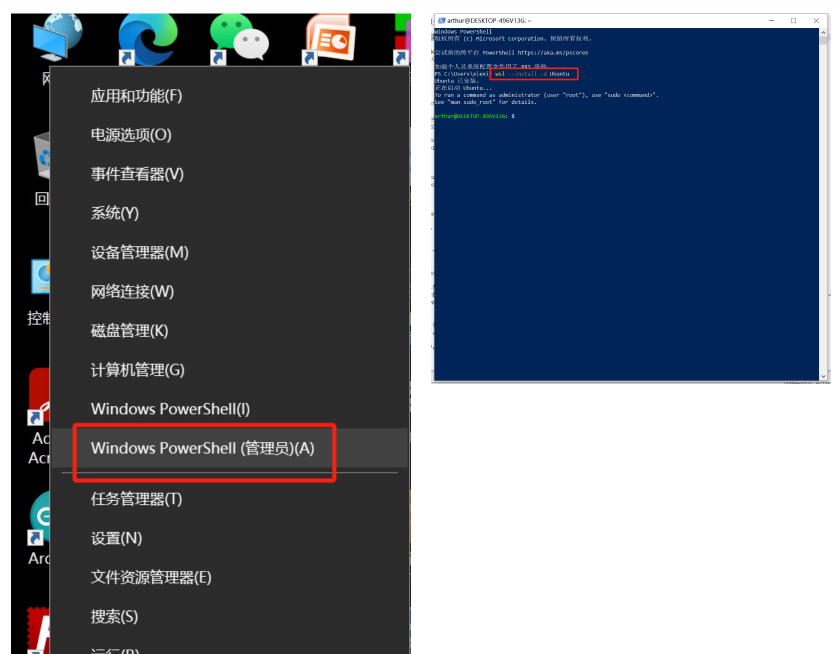
1、鼠标右键点击开始按钮,选择“Windows PowerShell(管理员)”选项,用管理员的方式打开powershell;
{kind=link}
wsl --install -d Ubuntu这条命令会让系统将ubuntu系统安装到你的windows电脑中,由于我已经安装过了,所以显示ubuntu已经安装!
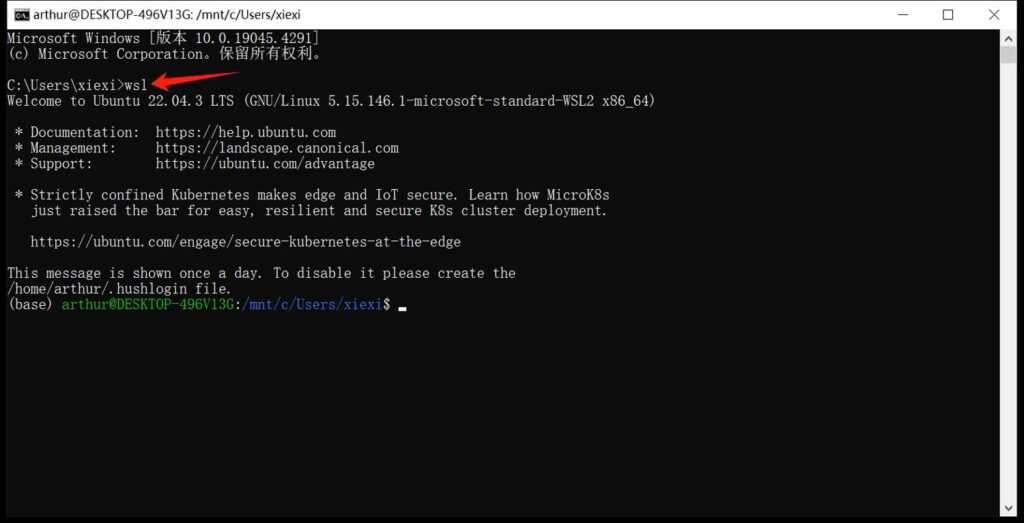
检查wsl是否安装成功,可以随便打开一个cmd命令窗口,输入“wsl”命令,如果显示wsl的相关信息,就证明安装成功了,否则会报错提示没有这个命令!
安装Docker Desktop
可以直接下载安装文件进行安装,文件下载地址:https://www.docker.com/products/docker-desktop/
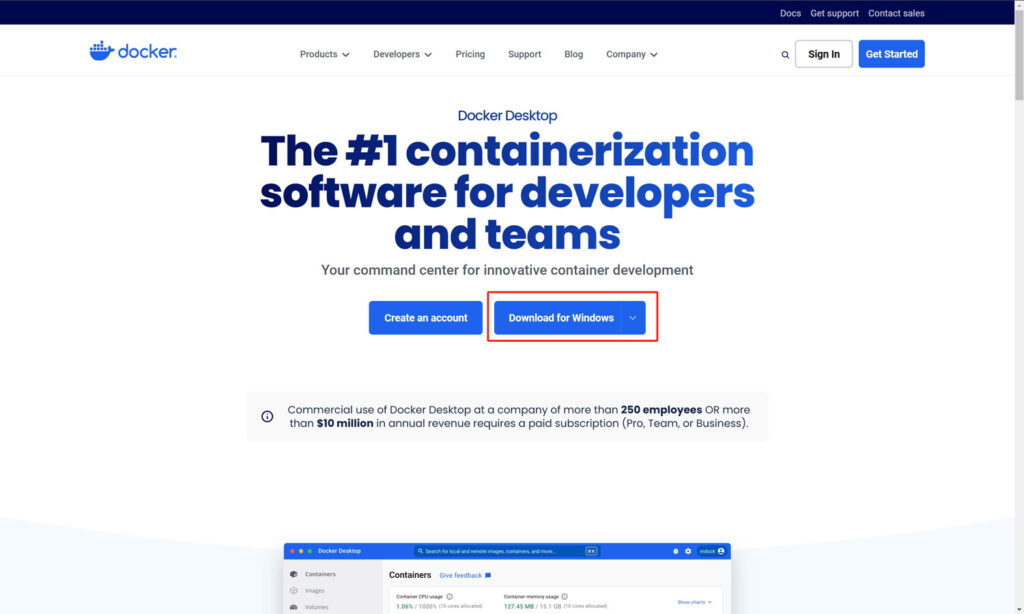
在下拉选框中选择windows的安装文件下载,下载完成之后双击安装即可!
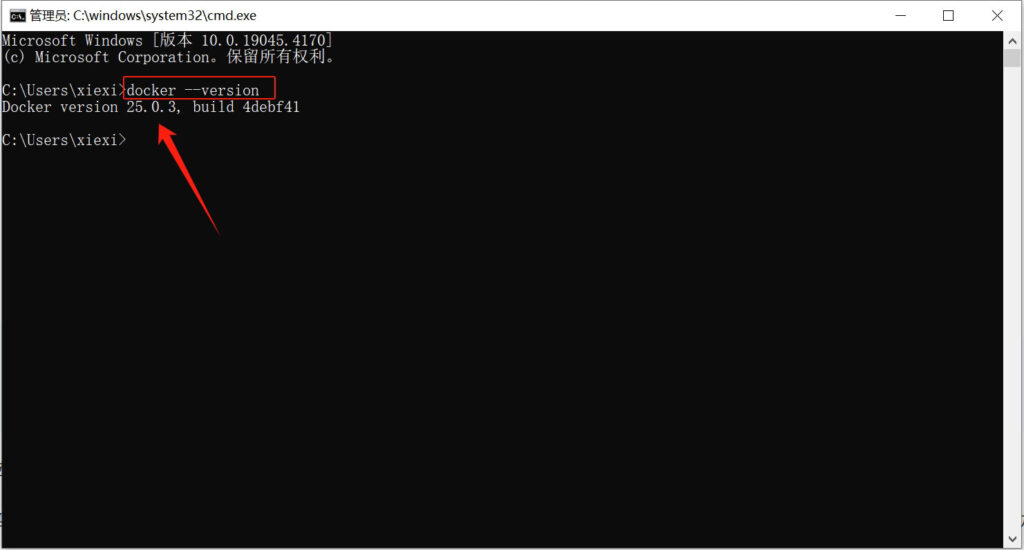
检查是否安装成功可以打开一个cmd窗口,或者powershell窗口,输入“docker –version”,如果可以正常显示docker的版本信息,则说明安装已经成功!
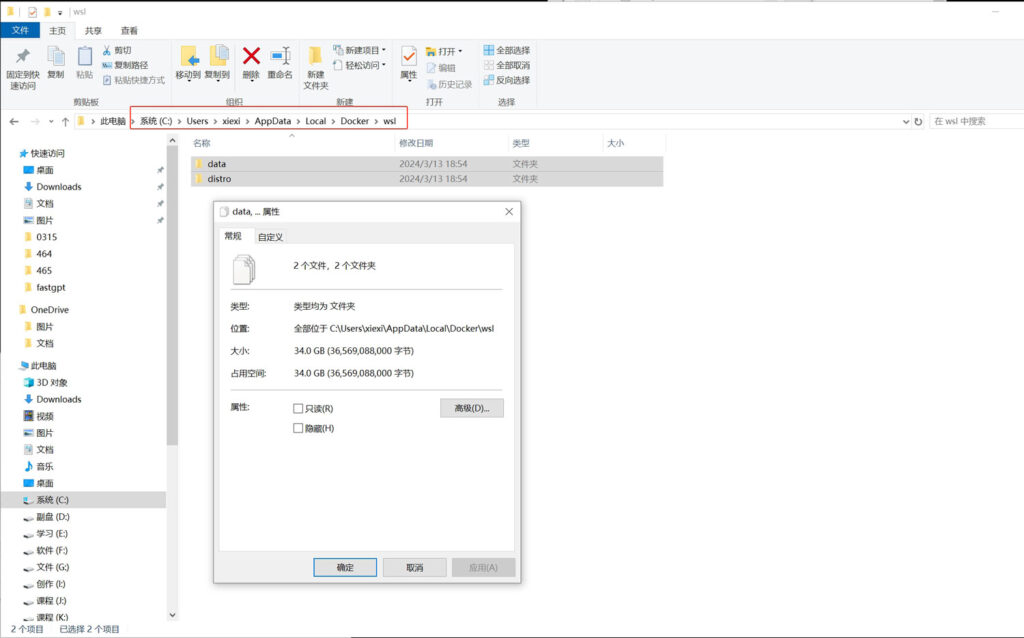
docker默认是安装在C盘中,docker运行时下载的程序镜像文件也是保存在C盘! 在windows10下docker下载的镜像文件默认保存在“C:Users用户名AppDataLocalDockerwsl”文件夹中;
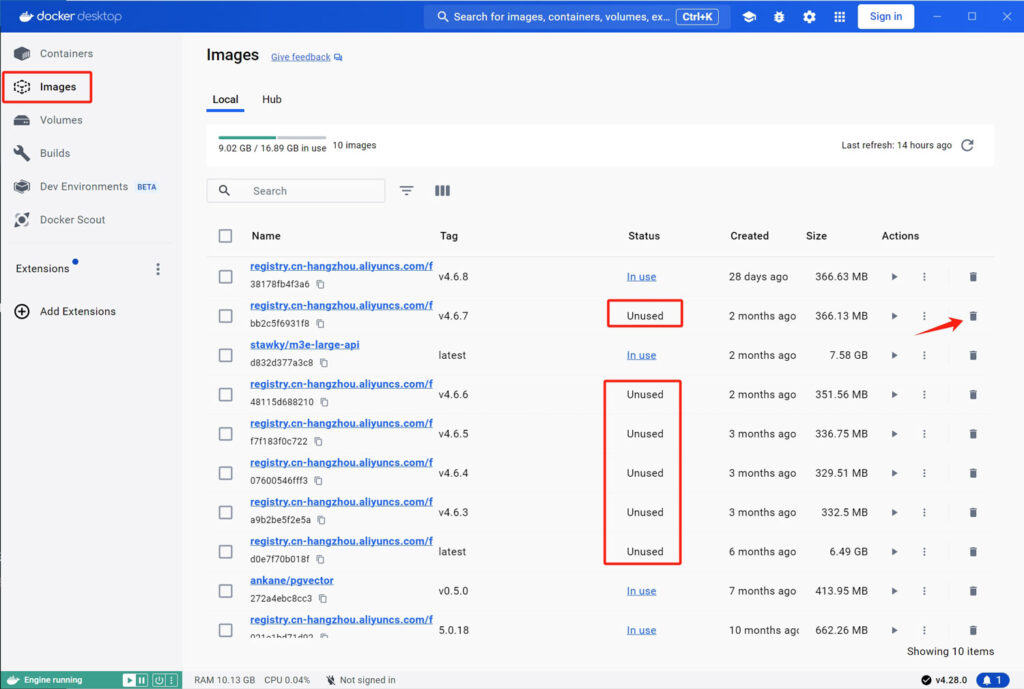
如果你需要在docker中运行的程序较多的话,一定要保证C盘有充足的磁盘空间!也可以通过Docker Desktop经常将docker中没用的镜像文件及时删除!
当然,你也可以通过cmd命令来删除指定的文件
删除停止的容器:
docker container prune删除未被任何容器引用的镜像:
docker image prune -a
删除未使用的网络:
docker network prune
删除未使用的卷:
docker volume prune
一键清除所有未使用的对象(包括镜像、容器、卷和网络):
docker system prune -a
安装Open WebUI
在docker desktop处于运行状态的情况下,随便打开一个cmd命令窗口,然后输入如下的命令来安装open webui
使用CPU运行
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
使用GPU运行
docker run -d -p 3000:8080 --gpus=all -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollama
安装完成之后,可以通过本地地址:http://127.0.0.1:3000 进行访问
初始化设置
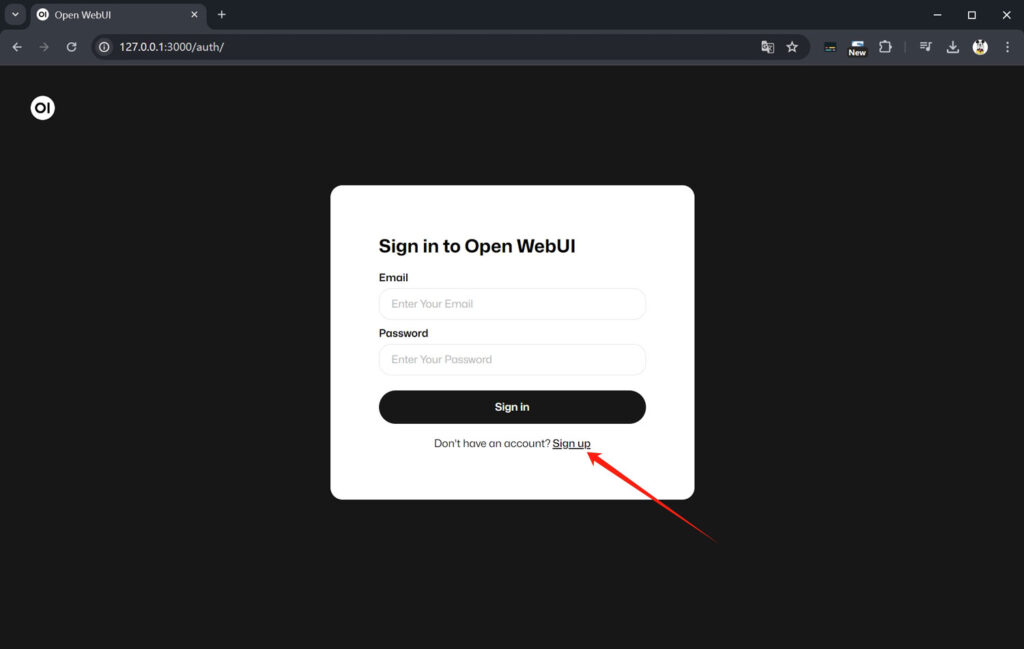
首次登录open webui需要注册一个账号,点击“Sign up”
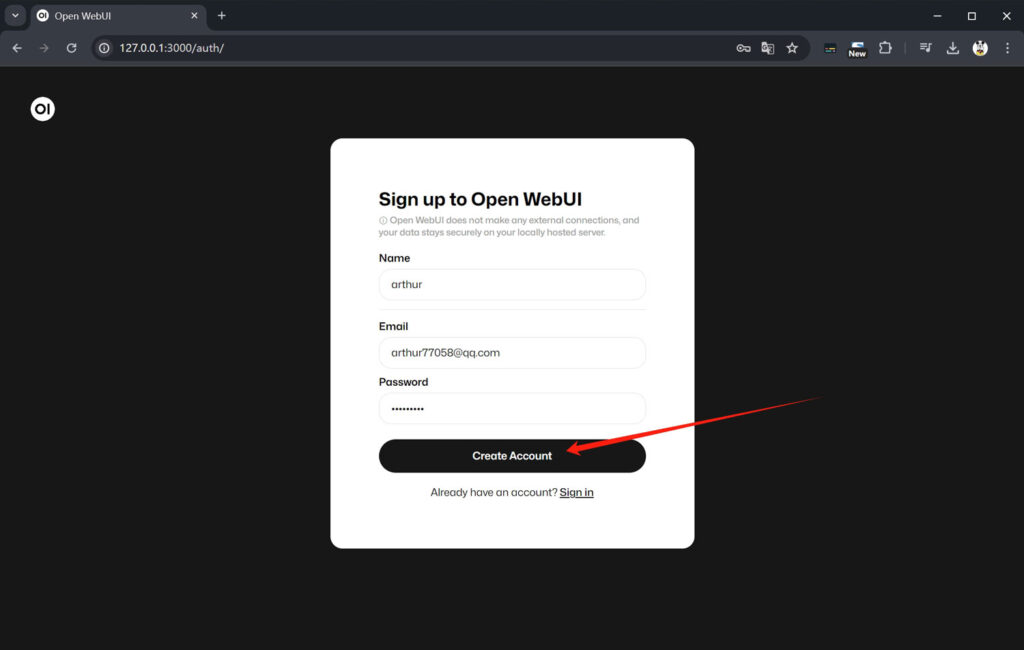
填写“name”、“Email”、“Password”之后,点击“Create Account”,创建一个账户
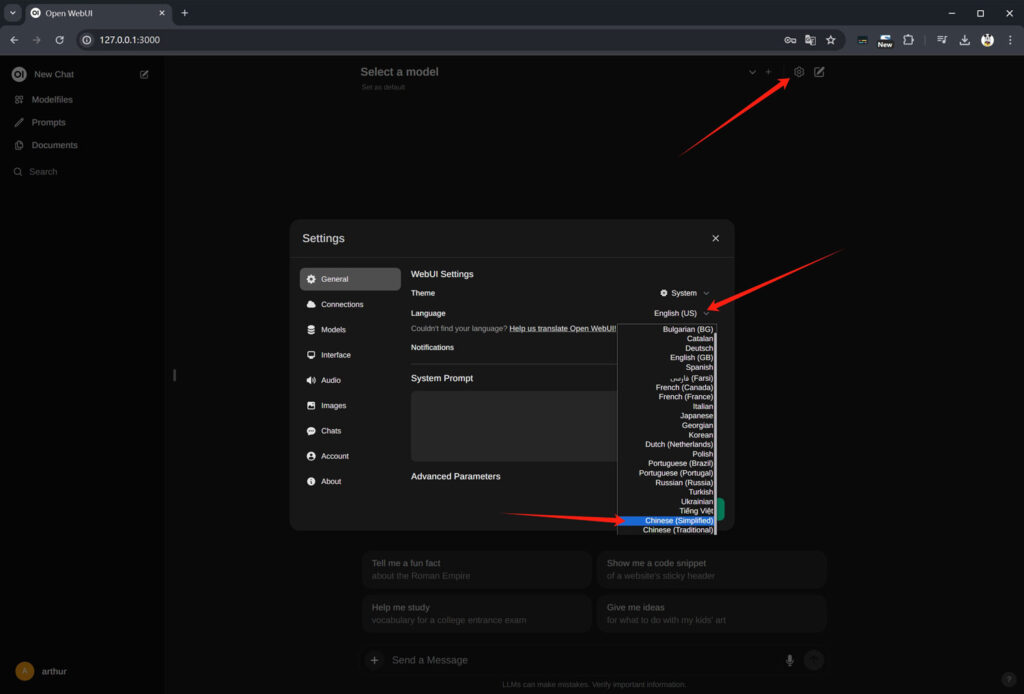
初次登入系统默认是英文界面,可以通过“设置”-“General”-“Language”来设置为“Chinese(Simplified)”简体中文!保存设置!
下载模型
安装了open webui之后,我们就不需要从“cmd”命令窗口去下载模型了,可以通过“设置”中的“模型”选项,填写模型的tag,直接从open webui下载模型!
模型的保存路径为“root/.ollama/models/”
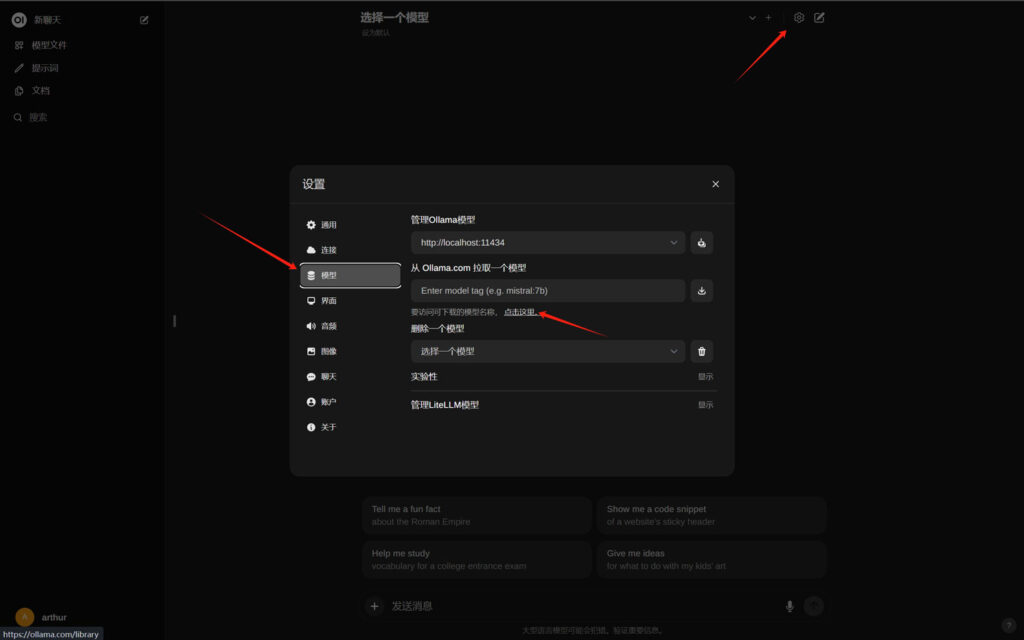
模型的tag查找方式与单独使用ollama下载模型的方法中提到的tag查找方法一致!
聊天
聊天界面的基本功能如下所示
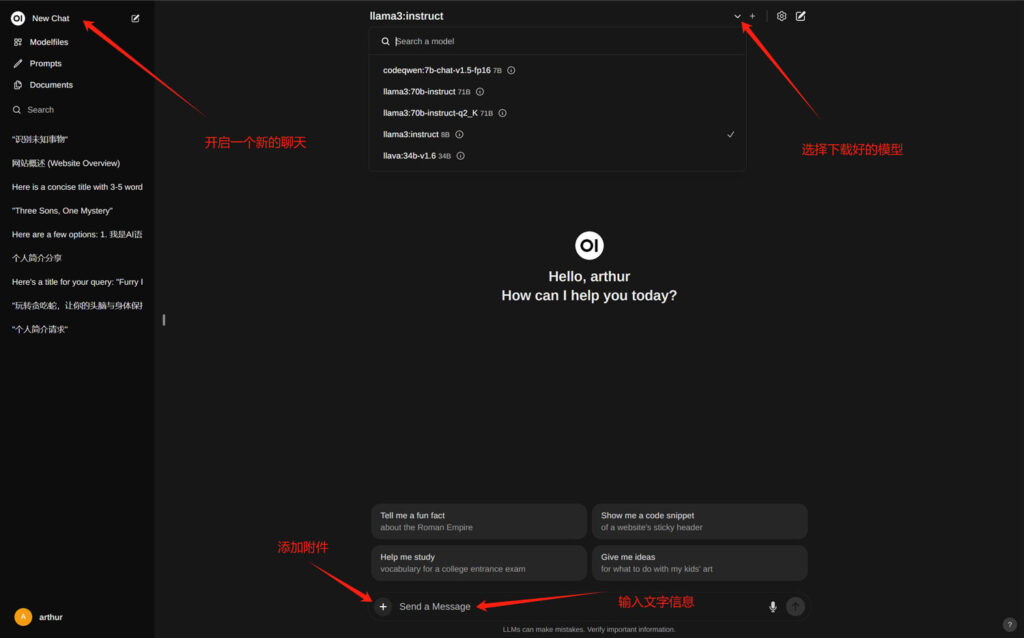
案例展示:
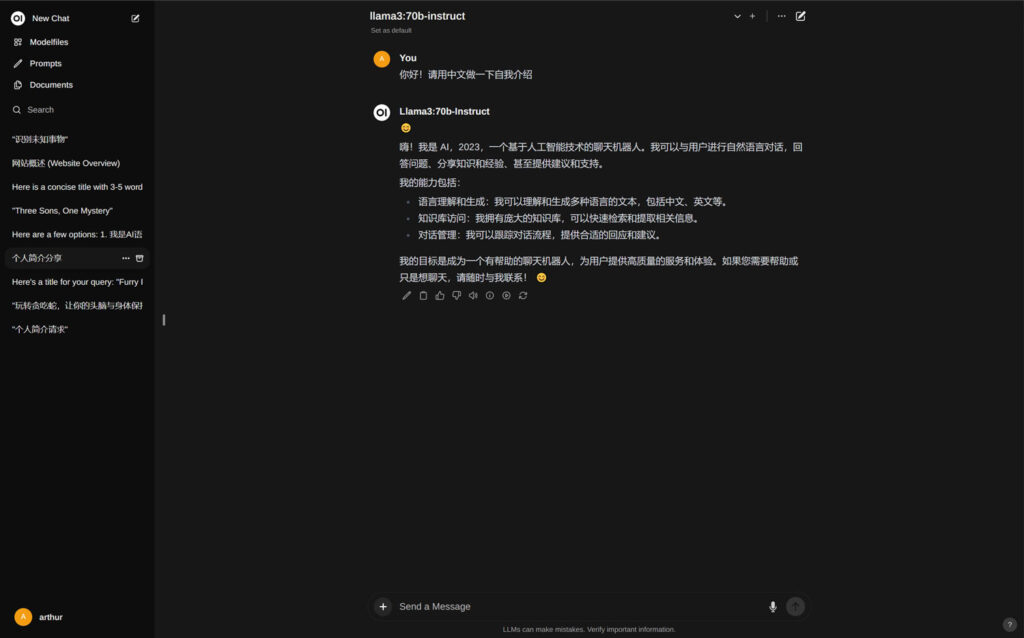
一、调用“llama3-70B-Instruct”模型,实现纯文本聊天;
二、调用“codeqwen1.5-7b-chat-fp16”模型,写代码;

三、上传附件文档或者网址,实现RAG检索增强功能;

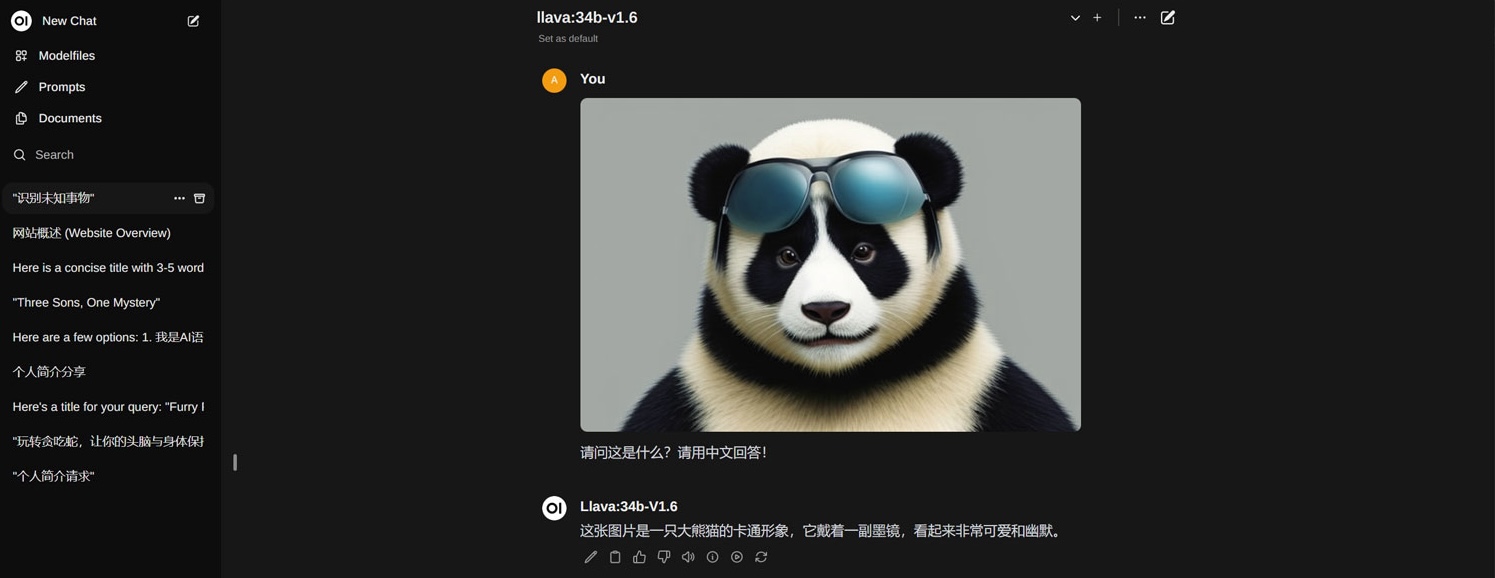
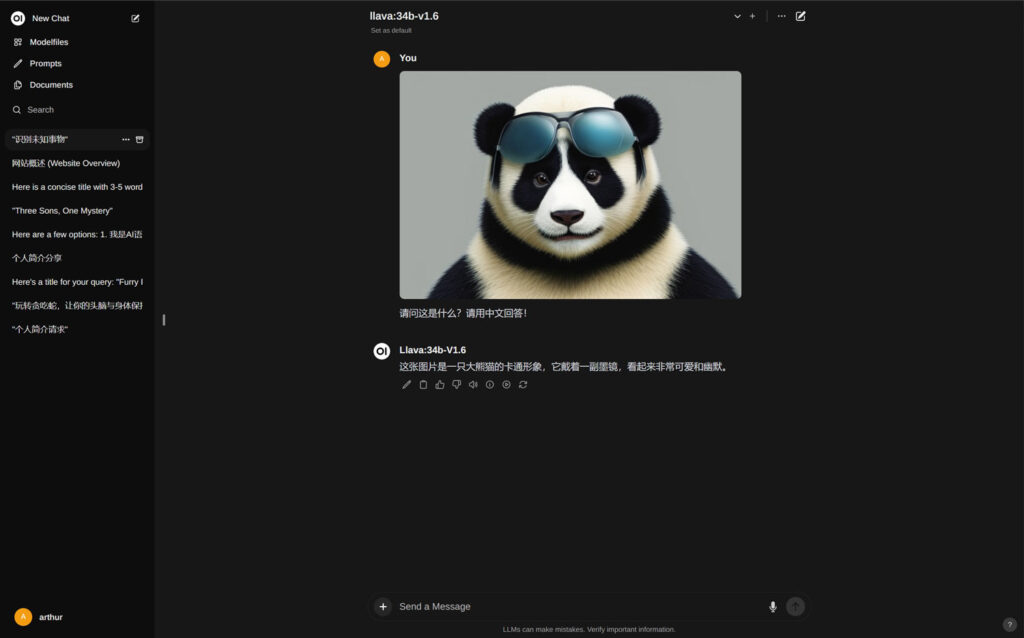
四、调用“llava-34B”多模态大模型,实现图片分析功能;
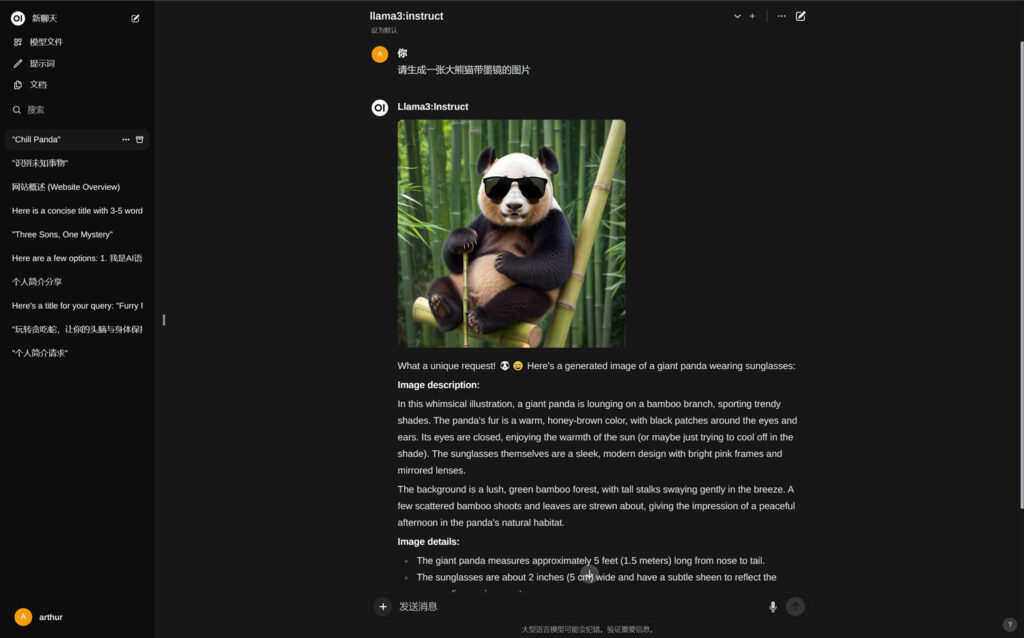
五、调用stable diffusion 的api接口,用LLM来指导SD直接在open webui中生成图片;
详细的配置流程我会另外出教程,由于篇幅问题我这里就不详细解释了!
总结
Ollama+Open WebUI的方案是一个非常卓越的整合方案,不仅可以本地统一管理和使用单模态和多模态的各种大模型,还可以本地整合LLM(大语言模型)和SD(稳定扩散模型)甚至是TTS(文本转语音)等各种AIGC程序和模型!是非常值得学习和熟练掌握的开源方案!
Ollama+Open WebUI+AUTOMATIC1111实现LLM+SD生成图片
主要介绍如何在open webui中调用automatic1111的api来生成图片
修改webui-user.bat
要在open webui中调用automatic1111的api接口,我们首先需要修改automatic1111的启动文件,打开并监听api;
在automatic1111的项目根目录中找到“webui-user.bat”批处理文件,右键点击,选择“编辑”,用记事本打开该文件,在“set COMMANDLINE_ARGS=”参数后面加上“–api –listen”
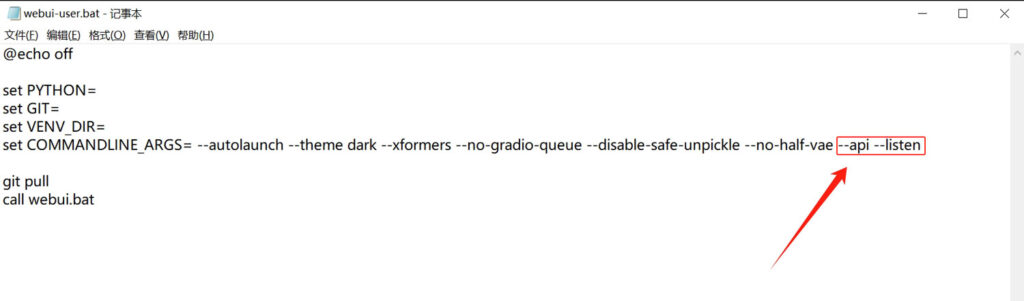
修改之后保存文件!
设置Open WebUI
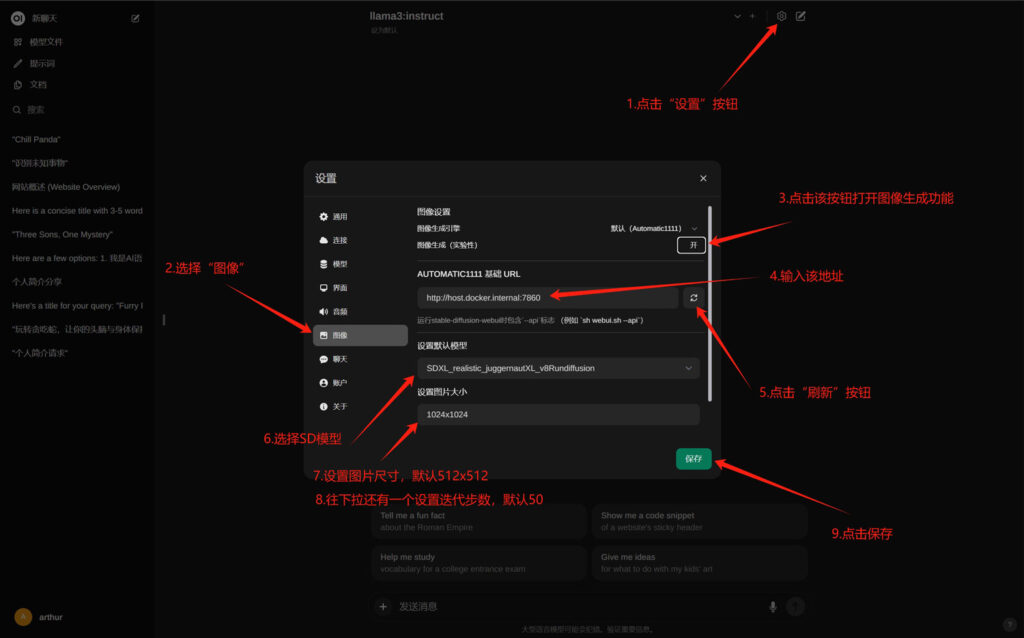
1.点击“设置”按钮;
2.选择“图像”设置;
3.点击图像生成开关,打开图像生成功能;
4.在“AUTOMATIC1111基础URL”一栏输入下面的链接:
http://host.docker.internal:7860
5.点击链接后面的“刷新”按钮;
6.点击了“刷新”按钮之后,就可以获取到本地AUTOMATIC1111的模型列表,可以从下拉列表中选择你喜欢的SD模型;
7.设置图片尺寸,默认为512×512,如果选择了一个SDXL模型,这里可以设置为1024×1024,或者其他SDXL支持的分辨率;
8.设置迭代步数,默认50步;
9.保存设置;
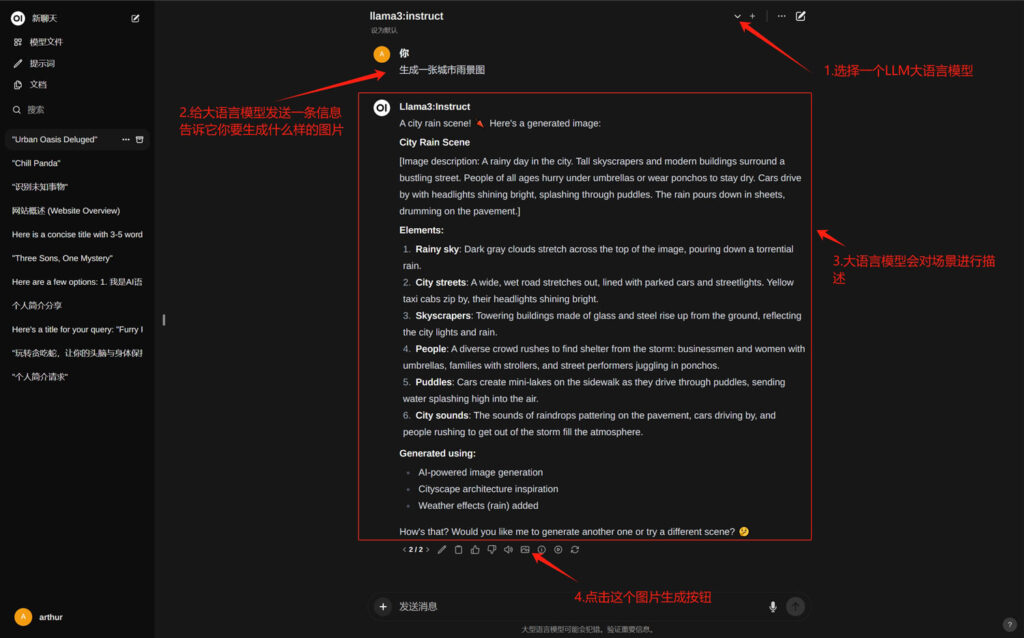
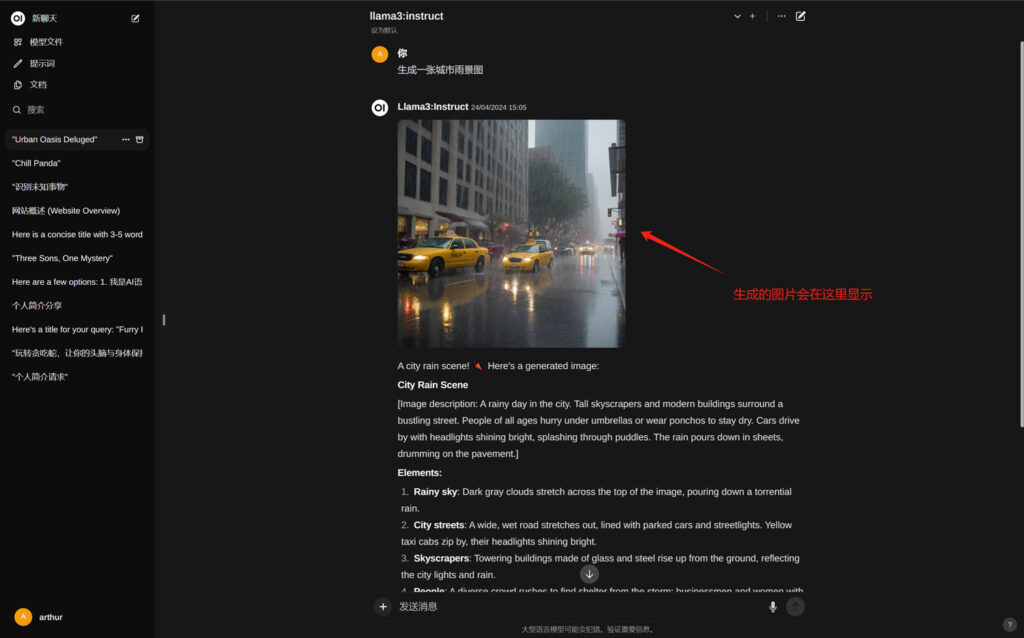
生成图片
按照正常的聊天方式,向LLM发送一个生成图片的请求,LLM会根据你的请求对画面进行描述,然后点击后面的“生成图片”按钮,程序就会通过API调用AUTOMATIC1111来生成一张相对应的图片,并且显示在LLM答案的顶部;
发表评论