
微软宣布推出Phi-3 系列开放小语言模型 (SLM),并宣称它们是现有规模中功能最强大、最具成本效益的模型。微软研究人员开发的创新训练方法使 Phi-3 模型在语言、编码和数学基准方面优于更大的模型。
“我们将开始看到的不是从大到小的转变,而是从单一类别模型到模型组合的转变,客户能够决定最适合他们的模型。场景,”微软生成人工智能首席产品经理 Sonali Yadav 说道。
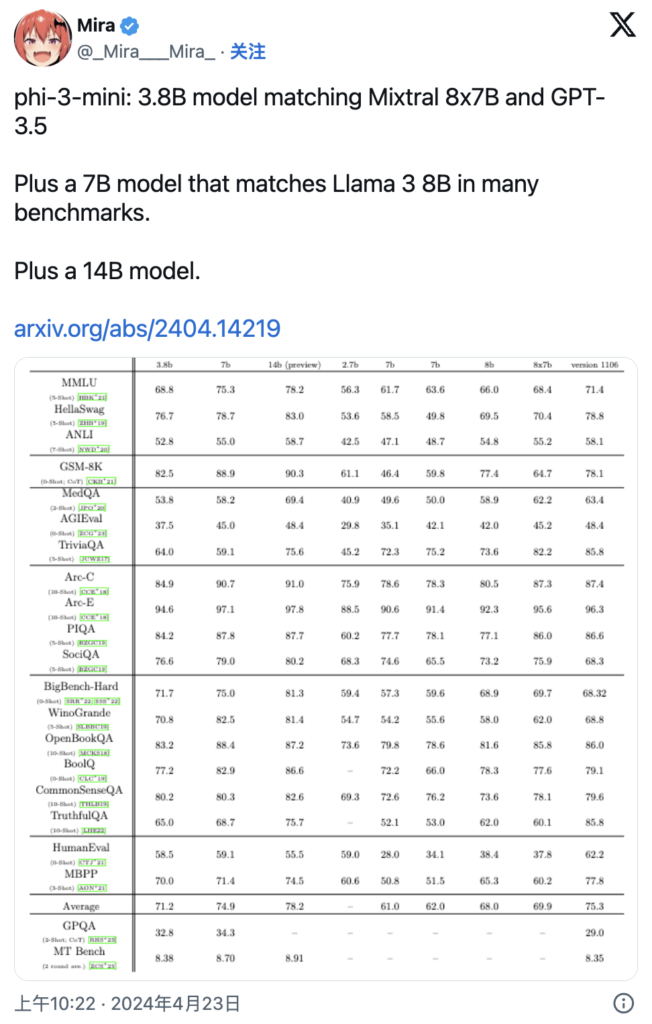
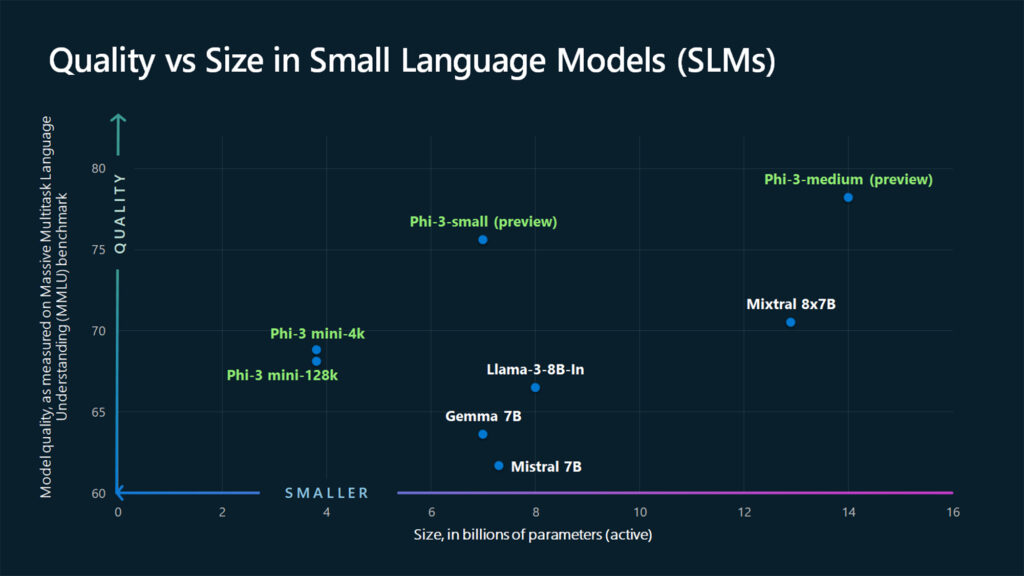
第一个 Phi-3 模型 Phi-3-mini 拥有 38 亿个参数,现已在Azure AI 模型目录、Hugging Face、Ollama中公开提供,并作为NVIDIA NIM微服务提供。尽管尺寸紧凑,Phi-3-mini 的性能优于两倍尺寸的型号。其他 Phi-3 模型,如 Phi-3-small(7B 参数)和 Phi-3-medium(14B 参数)即将推出。
微软人工智能副总裁 Luis Vargas 表示:“有些客户可能只需要小型模型,有些客户需要大型模型,而许多客户则希望以各种方式将两者结合起来。”
SLM 的主要优势是尺寸较小,无需网络连接即可在设备上部署低延迟 AI 体验。潜在的用例包括智能传感器、摄像头、农业设备等。将数据保存在设备上的另一个好处是隐私。
大型语言模型 (LLM) 擅长对海量数据集进行复杂推理,通过理解科学文献中的相互作用,适合药物发现等应用。然而,SLM 为更简单的查询回答、摘要、内容生成等提供了令人信服的替代方案。
Iris.ai首席技术官兼联合创始人 Victor Botev 评论道:“微软并没有追求更大的模型,而是开发具有更精心策划的数据和专门培训的工具。”
“这可以提高性能和推理能力,而无需花费数万亿参数的模型的大量计算成本。实现这一承诺意味着为寻求人工智能解决方案的企业消除巨大的采用障碍。”
突破训练技术
Microsoft SLM 质量飞跃的推动者是受睡前故事书启发的创新数据过滤和生成方法。
“与其仅使用原始网络数据进行训练,为什么不寻找质量极高的数据呢?”负责 SLM 研究的 Microsoft 副总裁 Sebastien Bubeck 问道。
Ronen Eldan 每天晚上与女儿一起阅读的习惯激发了他的想法,即通过用 4 岁孩子会知道的单词组合提示一个大型模型来生成包含数百万个简单叙述的“TinyStories”数据集。值得注意的是,在 TinyStories 上训练的 10M 参数模型可以生成具有完美语法的流畅故事。
在早期成功的基础上,该团队采购了经过教育价值审查的高质量网络数据,以创建“CodeTextbook”数据集。这是通过人类和大型人工智能模型的多轮提示、生成和过滤来合成的。
“生成这些合成数据需要花费很多心思,”布贝克说。 “我们不会拿走我们生产的所有东西。”
事实证明,高质量的训练数据具有变革性。 “因为它是从类似教科书的材料中读取的……你可以使语言模型的阅读和理解这些材料的任务变得更加容易,”布贝克解释道。
降低人工智能安全风险
尽管数据管理经过深思熟虑,微软仍然强调在 Phi-3 版本中应用额外的安全实践,以反映其所有生成式 AI 模型的标准流程。
“与所有生成式 AI 模型版本一样,微软的产品和负责任的 AI 团队使用多层方法来管理和降低开发 Phi-3 模型的风险,”一篇博客文章指出。
这包括进一步的培训示例以强化预期行为、通过红队进行评估以识别漏洞,以及为客户提供 Azure AI 工具以在 Phi-3 上构建值得信赖的应用程序。
发表评论