
Reka Core是一款最新发布的多模态大型语言模型(LLM),其性能可与GPT-4相媲美,甚至在某些方面超越了现有的前沿模型。这一技术突破为人工智能领域带来了新的里程碑,特别是在图像、视频和音频的上下文理解能力方面。
Reka是一家全球分布的基础模型初创公司,总部位于加利福尼亚州桑尼维尔。我们是一家远程优先的公司,人才遍布世界各地。Reka的员工分布在加利福尼亚、西雅图、伦敦、苏黎世、香港和新加坡等地。
Reka是一个小而凶猛的团队,由来自 DeepMind、Google Brain 和 FAIR 的研究科学家和工程师创立。创始团队以及许多团队成员在过去十年中为人工智能领域的许多突破做出了贡献。
官方网址:https://chat.reka.ai/auth/login
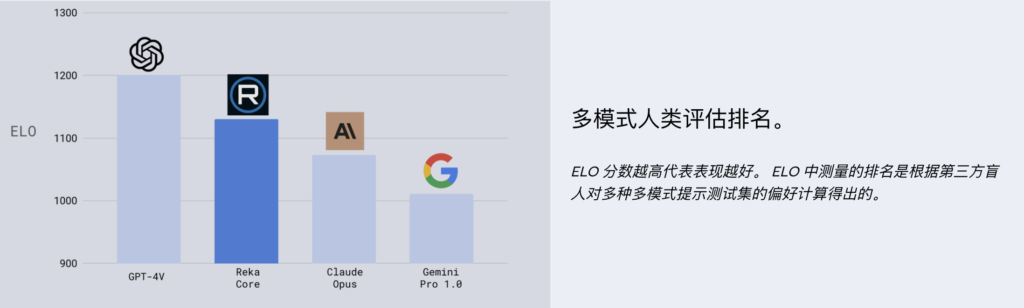
在多模态理解和生成方面,Reka Core展现了卓越的性能。在与GPT-4V的比较中,Core在多模态混合理解单元(MMMU)方面表现出色,能够与GPT-4V相媲美。在独立第三方机构进行的多模态人类评估中,Core的性能甚至超过了Claude-3Opus。此外,在视频任务方面,Core的性能超越了Gemini Ultra,而在语言任务方面,Core在成熟的基准测试中也能与其他顶尖模型相媲美,显示出其全面而强大的能力。
支持中文输入
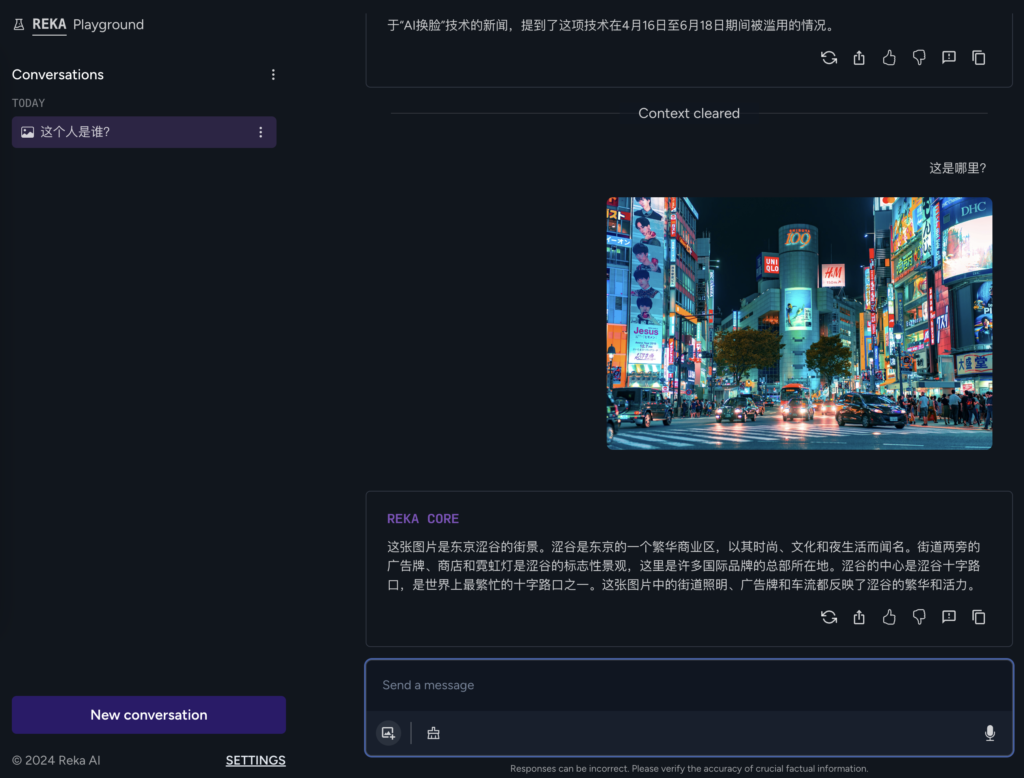
在图像识别和文字识别上,是优于GPT4的,只是对识别人物还是有优化的地方:

功能特点:
多模态理解: Reka Core不仅仅是一个先进的大型语言模型,它还能够理解和生成图像和视频内容。这使得Core成为市场上仅有的两个商用综合多模态解决方案之一,能够为用户提供更加丰富和全面的交互体验。
上下文窗口: Core拥有128K的上下文窗口,这意味着它能够处理和调用更多的信息,从而提供更加精确和细致的输出结果。
推理能力: Core具备超强的推理能力,无论是语言还是数学问题,它都能够进行精密的分析和解答,适合执行复杂的任务。
编码和Agent工作流程: 作为一个顶级的代码生成器,Core的编码能力与其他功能相结合,可以显著增强Agent工作流程的能力,为用户提供更加高效和智能的服务。
多语言支持: Core在32种语言的文本数据上进行了预训练,不仅能够流利地使用英语,还能够支持多种亚洲和欧洲语言,这使得Core能够服务于全球更广泛的用户群体。
灵活部署: 与其他模型一样,Core可以通过应用程序接口、内部部署或设备等多种方式进行部署,以满足客户和合作伙伴的不同部署需求和限制。
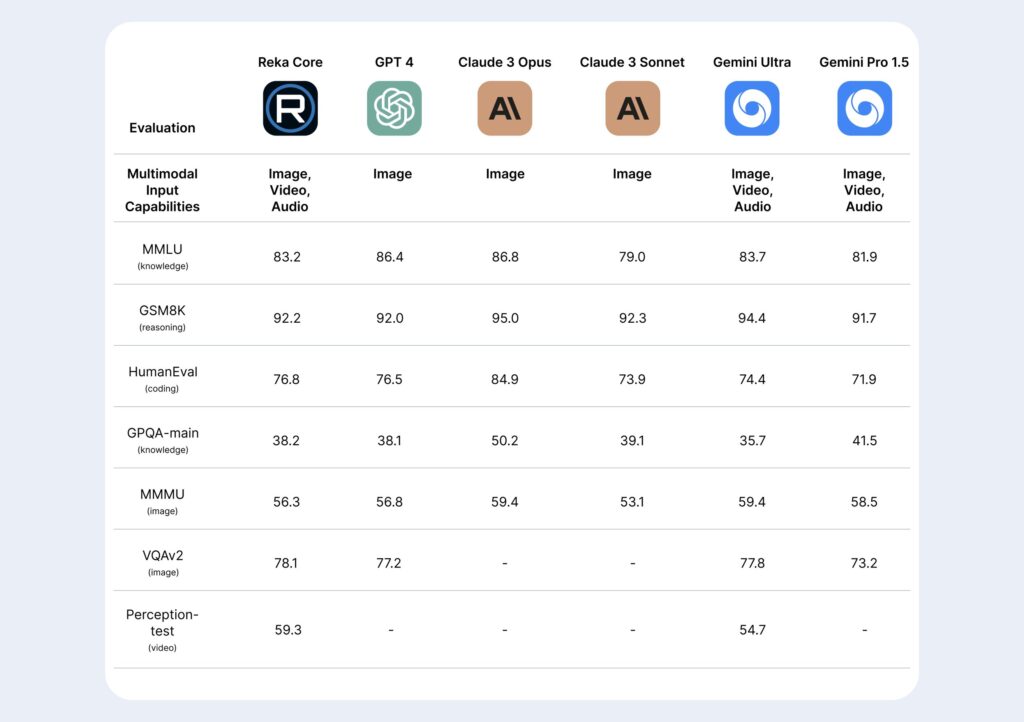
下表总结了 Core 与当今市场领先型号的比较。
资料来源:瑞卡内部信息、公司网站、公开披露信息、技术报告。 “-”表示由于模型能力而未披露或不相关/适用的数据。
Reka Core的发布标志着人工智能技术在多模态理解和生成方面迈出了重要的一步。它的出现不仅为用户提供了更加强大和灵活的工具,也为未来的技术发展和应用开辟了新的可能性。随着Core的进一步优化和应用,我们有理由相信,它将在多个领域产生深远的影响,推动人工智能技术的进步和社会的发展。
发表评论