
官方网址:https://www.microsoft.com/en-us/research/project/vasa-1/
论文链接:https://arxiv.org/pdf/2404.10667.pdf
VASA这是一个框架,可以在给定单个静态图像和语音音频剪辑的情况下,生成具有吸引人的视觉情感技能 (VAS) 的虚拟角色的逼真说话面孔。
首屈一指的模型 VASA-1 不仅能够产生与音频完美同步的嘴唇运动,还能捕捉大量面部细微差别和自然头部运动,有助于感知真实性和活力。
核心创新包括在面部潜在空间中工作的整体面部动态和头部运动生成模型,以及使用视频开发这种富有表现力和解开的面部潜在空间。
通过广泛的实验,包括对一组新指标的评估,VASA-1的方法在各个维度上都显着优于以前的方法。VASA-1的方法不仅提供具有逼真的面部和头部动态的高视频质量,而且还支持在线生成 512×512 视频,帧速率高达 40 FPS,启动延迟可以忽略不计。 它为与模仿人类对话行为的逼真化身进行实时互动铺平了道路。
现实主义和生动性
VASA-1的方法不仅能够产生珍贵的唇音同步,还能产生大量富有表现力的面部细微差别和自然的头部运动。它可以处理任意长度的音频并稳定输出无缝的说话人脸视频。
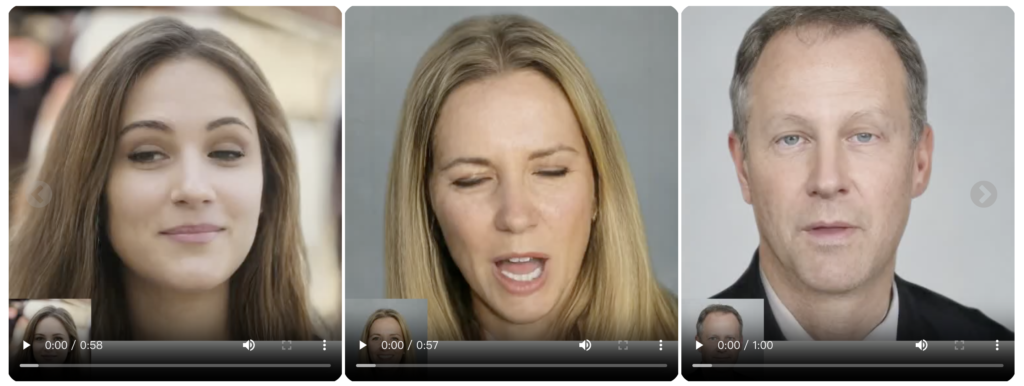
发电可控性
VASA-1的扩散模型接受可选信号作为条件,例如主眼注视方向和头部距离以及情绪偏移。
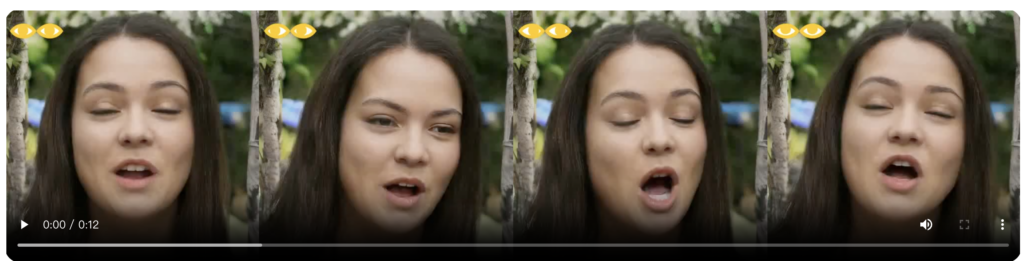


分布外泛化
VASA-1的方法展示了处理训练分布之外的照片和音频输入的能力。例如,它可以处理艺术照片、歌唱音频和非英语语音。这些类型的数据不存在于训练集中。

解开纠缠的力量
VASA-1的潜在表示解开了外观、3D 头部姿势和面部动态,这使得能够对生成的内容进行单独的属性控制和编辑。


实时效率
VASA-1的方法在离线批处理模式下以 45fps 生成 512×512 大小的视频帧,并在在线流模式下支持高达 40fps,且前期延迟仅为 170ms,在具有单个 NVIDIA RTX 4090 GPU 的台式电脑上进行评估。
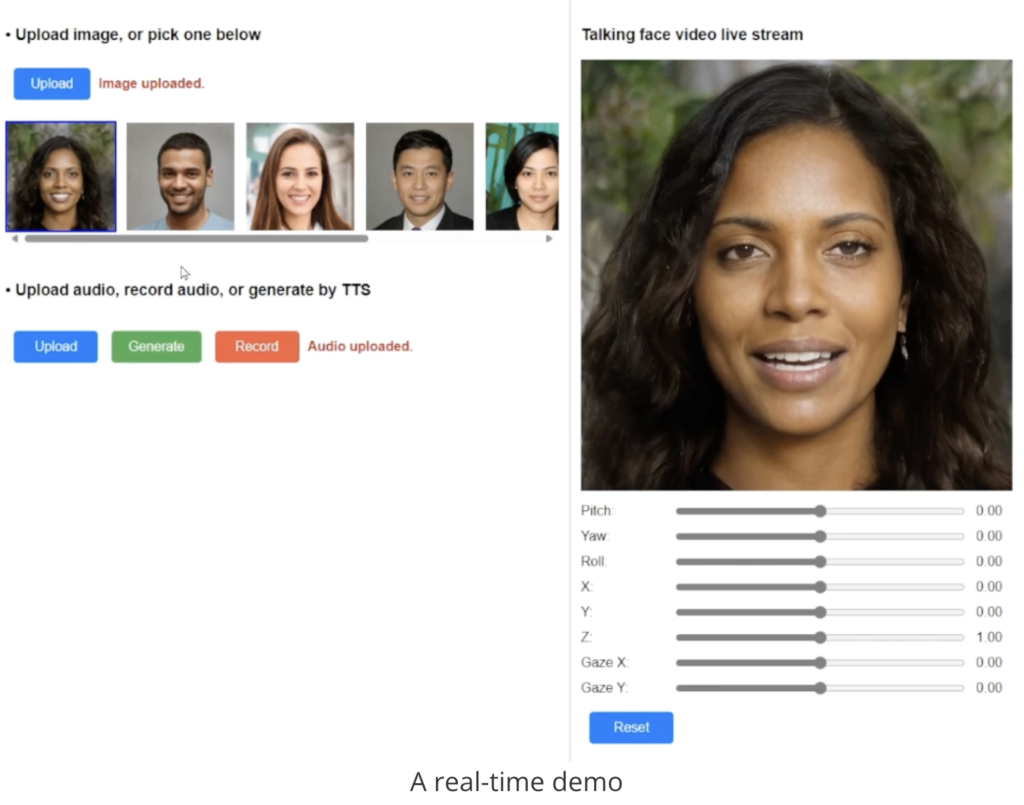
风险和负责任的人工智能考虑因素
VASA-1的研究重点是为虚拟人工智能化身生成视觉情感技能,旨在实现积极的应用。
无意创建用于误导或欺骗的内容。然而,与其他相关内容生成技术一样,它仍然可能被滥用于模仿人类。VASA-1反对任何创造真实人物的误导性或有害内容的行为,并且有兴趣应用我们的技术来推进伪造检测。
目前,该方法生成的视频仍然包含可识别的伪影,数值分析表明,距离真实视频的真实性仍有差距。 在承认滥用的可能性的同时,必须认识到我们的技术的巨大积极潜力。好处——例如增强教育公平、改善有沟通障碍的个人的可及性、提供陪伴或 向有需要的人等提供治疗支持强调了我们的研究和其他相关探索的重要性。 我们致力于负责任地开发人工智能,以促进人类福祉为目标。 鉴于这种背景,我们没有计划发布在线演示、API、产品、其他实施细节或任何相关产品,直到我们确定该技术将被负责任地使用并符合适当的法规。
发表评论